CapRL: 用强化学习激发视觉语言模型的描述能力
Published:
Paper: CapRL: Stimulating Dense Image Caption Capabilities via Reinforcement Learning (CVPR 2025)
Authors: Xing et al.
TL;DR: CapRL提出了一种新颖的强化学习框架,通过将主观的”描述好不好”问题转化为客观的”问题能否答对”问题,有效解决了图像描述任务中的reward hacking难题,显著提升了模型生成稠密、准确(Dense and Accurate)描述的能力。
1. 引言:一个“简单”任务的深层挑战
图像描述(Image Captioning)看似是一个直观的任务——给定一张图片,让模型生成一段描述文字。然而,当我们追问”什么样的描述才是好的描述”时,事情变得复杂起来。这篇论文致力于解决图像描述生成领域的一个核心难题:如何让模型生成既信息丰富(Dense)又准确无误(Accurate)的图像描述。 传统方法通常采用监督式微调(SFT),让模型学习”模仿”人类标注的描述。但这种方法面临几个根本性问题: 

成本高昂且扩展性差:获取大规模、高质量的标注数据既昂贵又耗时,限制了模型的进一步发展。
缺乏泛化性和创造性:模型倾向于“背诵”训练数据中的特定描述,导致生成的描述比较单一,难以覆盖同一张图片可能存在的多种合理解释,创造性和多样性不足。
主观性难题:对于同一张图片,什么样的描述才算“好”本身就是一个主观问题。传统的评价指标(如BLEU、ROUGE)难以评估描述的丰富性和准确性。
为了克服SFT的局限性,研究者自然想到用强化学习(RL)来打破这些限制——让模型在探索中学习,而非死记硬背。但这引出了一个更棘手的问题:如何定义奖励函数(Reward Function)?
2. 现有RL方法的困境:Reward Hacking
早期的尝试,例如使用另一个大型视觉语言模型(LVLM)作为“裁判”(LVLM-as-a-Judge)来打分,被证明存在固有的偏见(例如,可能偏爱更长或更简短的描述),容易发生Reward Hacking,导致训练不稳定甚至崩溃。 
2.1 “裁判”的偏见
任何模型都有其内在偏好:
通用LVLM往往偏爱冗长、详细的描述
通用奖励模型可能被训练得偏好简洁的输出
2.2 策略模型的”钻空子”
聪明的策略模型很快学会了利用裁判的偏见:
# 面对偏爱冗长的裁判
输出: "我的描述组织得很好,结构很完善,首先我要说明..."
结果: 高分!但完全没描述图像内容
# 面对偏爱简洁的裁判
输出: "图中有三只动物"
结果: 高分!但信息量极低
这就是臭名昭著的Reward Hacking——模型找到了获取高奖励的”捷径”,却完全偏离了我们的真实目标。 更糟糕的是,这种现象会导致训练过程极不稳定,甚至训练崩溃(Training Collapse)。因此,该论文的核心目标是为图像描述任务设计一个客观、可验证且可扩展的强化学习框架,从而激发模型生成更密集、更准确描述的能力。
3. CapRL的核心洞见
CapRL提出了一个精妙的思路来重新定义”好描述”:
一个高质量的图像描述,应该能让一个无法看到图像的纯语言模型,仅凭该描述就能准确回答关于图像的各种问题。
这个定义的巧妙之处在于:
客观可验证:问题回答对错是二元的,没有主观模糊空间
难以作弊:无法通过套话获得高分,必须包含实质信息
自然鼓励稠密性:覆盖更多细节 → 能回答更多问题 → 更高奖励
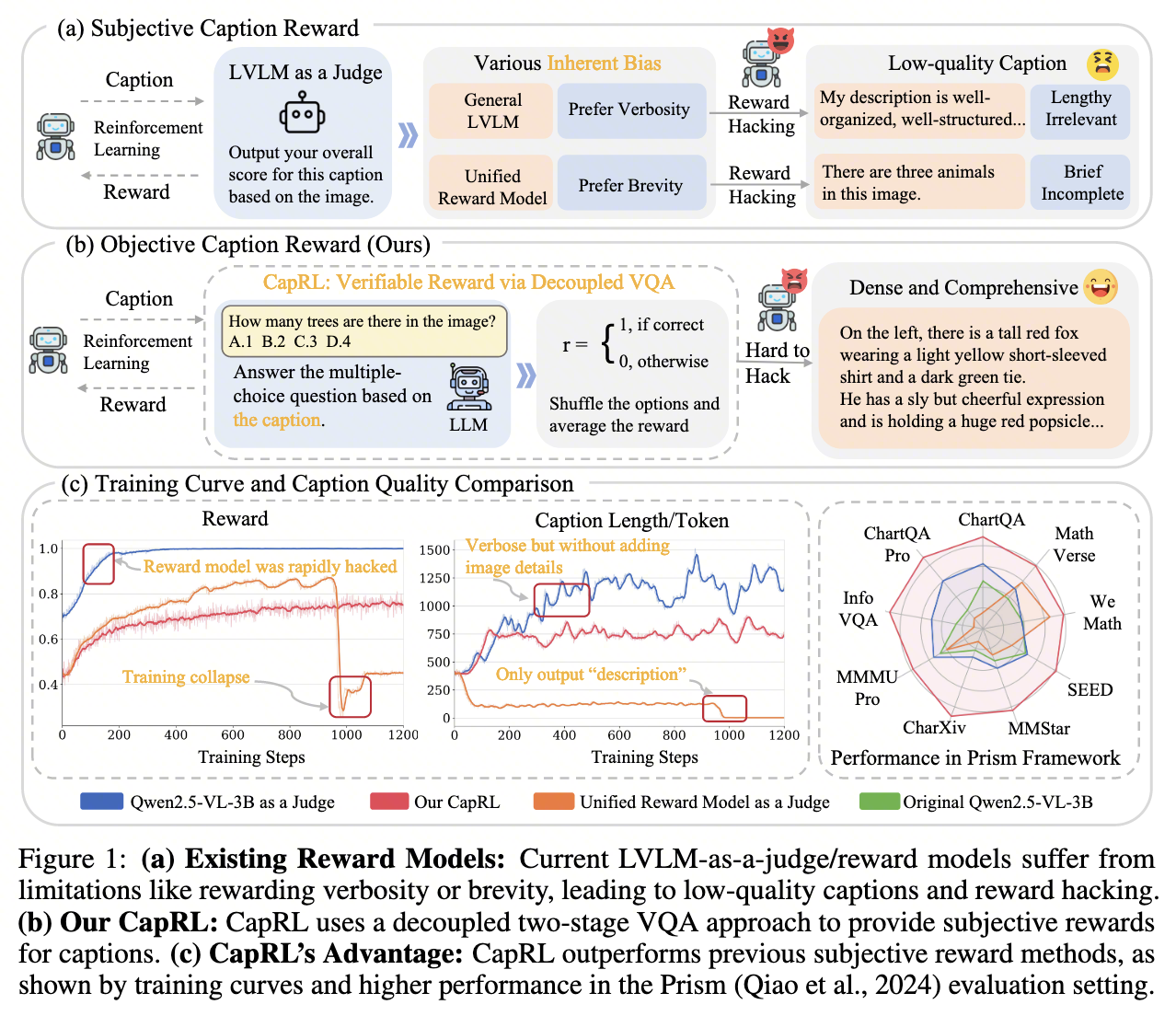
(a) Subjective Caption Reward (主观的描述奖励) - 阐述问题
这部分展示了当前主流的、基于“裁判模型”(LVLM as a Judge)的强化学习方法及其固有缺陷。
流程:一个强化学习智能体(Reinforcement Learning Agent)生成一个图像描述(Caption)。然后,这个描述被发送给一个大型视觉语言模型(LVLM as a Judge),这个“裁判”模型会根据图像给描述打一个主观的综合分数,这个分数作为奖励(Reward)返回给智能体,指导其后续学习。
- 核心缺陷:内在偏见 (Inherent Bias):这个“裁判”本身是有偏见的。
有些通用的LVLM可能偏爱更详细、更冗长的描述 (Prefer Verbosity)。
有些通用的奖励模型(Unified Reward Model)可能经过训练后偏爱更简洁的描述 (Prefer Brevity)。
- 结果:Reward Hacking:policy模型发现并利用“裁判”的这些偏见来“钻空子”,而不是真正学习如何生成好的描述。
为了迎合偏爱冗长的裁判,模型会生成一些“冗长但无关” (Lengthy Irrelevant) 的描述,比如“我的描述组织得很好,结构很完善…”,这些话术虽然能得到高分,但完全没有描述图像内容。
为了迎合偏爱简洁的裁判,模型会生成“简短但不完整” (Brief Incomplete) 的描述,比如“图中有三只动物”,信息量极低。
(b) Objective Caption Reward (Ours) (客观的描述奖励 - 我们的方法) - 提出方
这部分详细介绍了论文提出的CapRL方法,它构建了一个客观、可验证的奖励机制。
核心思想:通过解耦的视觉问答(Decoupled VQA)来验证奖励。一个好的描述,应该能让一个看不见图像的模型仅凭描述就能回答关于图像的问题。
优势:难以被攻击 (Hard to Hack):智能体无法通过生成无关的套话来获得高分。它必须生成包含问题答案所需信息的“密集且全面” (Dense and Comprehensive) 的描述,才能让LLM正确回答问题。CapRL方法将主观的“描述好不好”问题,巧妙地转化为了客观的“问题能否答对”的问题,从而创建了一个稳健、可靠的奖励信号。
(c) Training Curve and Caption Quality Comparison (训练曲线和描述质量对比) - 验证效果
这部分通过实验数据,从“过程”和“结果”两个维度证明了CapRL方法的优越性。
- 左侧图(Reward/奖励曲线)和中间图(Caption Length/描述长度曲线):展示了训练过程的稳定性。
蓝色曲线 (Qwen2.5-VL-3B as a Judge):奖励迅速达到1.0,但描述长度也急剧增加。这完美印证了(a)中提到的“奖励被攻击”,模型通过生成冗长无用的内容轻易获得了满分奖励。
橙色曲线 (Unified Reward Model as a Judge):训练非常不稳定,奖励在上升后突然“训练崩溃” (Training collapse),描述长度也骤降到几乎为零。
红色曲线 (Our CapRL):奖励曲线平滑、稳定地增长,没有被轻易“攻击”,描述长度也保持在一个合理的范围内。这表明CapRL提供了一个有意义且稳定的学习信号。
- 右侧雷达图 (Performance in Prism Framework):展示了最终模型的性能。
这是一个在多个基准测试(如ChartQA, MathVerse, SEED等)上的性能对比图,越靠外圈表示性能越好。
红色线 (Our CapRL) 在几乎所有维度上都显著优于其他模型,包括作为基线的原始模型(绿色)、以及其他两种奖励模型(蓝色和橙色)。
小结:这部分用数据证明,相比于现有的主观奖励方法,CapRL不仅训练过程更稳定,而且最终训练出的模型在各项任务上性能也更强大。
4. 高质量MCQ数据集构建
由于奖励机制的有效性高度依赖于问答数据的质量。研究团队首先构建了一个高质量的、与图像内容紧密相关的多项选择题问答(Multiple-Choice Questions, MCQs)数据集。这个数据集经过了严格的筛选,确保问题必须依靠图像信息才能回答,排除了仅靠常识或问题本身线索就能解答的“泄露”问题。
4.1 第一阶段:图像收集 (Image Collection)
这一步的目标是确保图像的多样性、高质量和安全性。
- 来源:从多个渠道收集图像,以确保模型能够处理各种类型的视觉信息。主要来源包括:
现有的高质量开源数据集:如ShareGPT4V-1M和DenseFusion-1M,这些数据集本身已经经过了一轮筛选。
网络搜集:涵盖了自然照片、文档、图表、用户界面等多种类别。
- 质量和安全过滤:对收集到的图像进行严格的过滤,去除低分辨率、过于简单、或包含暴力、色情等不安全内容的图片。同时,他们还移除了与常见评测基准中的图像高度相似的图片,以防止数据泄露(Benchmark Leakage)。
4.2 第二阶段:问答对生成 (QA Generation)
在收集好图像之后,为每张图片生成相应的问题和答案.
生成模型:使用 Qwen2.5-VL-72B
生成过程:对于数据集中的每一张图片,将图片输入Qwen2.5-VL-72B,并提示它生成多个与图片内容相关的多项选择题及其正确答案。

4.3 第三阶段:问答对筛选 (QA Filtering)
这是整个流程中最核心、最巧妙的一步。其目标是消除信息泄露(Information Leakage),确保每个留下的问题都必须通过看图才能回答。 “信息泄露”指的是,有些问题仅凭常识或问题本身的措辞就能回答,并不需要看图。例如,一张包含“Eiffel Tower”标志的图片,如果问题是“What is the capital of France?”,那么模型不需要看图就能回答“Paris”。这种问题对于评估描述质量是无效的。为了解决这个问题,设计了一个一正一反的双重验证机制:
- 正向验证 (保证问题可答):
测试方法:将“图片 + 问题”*一同输入给一个LVLM(论文中提到为了节约成本,筛选时用的是Qwen2.5-VL-3B)。
通过条件:模型必须能够正确回答问题。这确保了问题与图片内容相关,并且答案可以在图片中找到。
- 反向验证 (保证视觉依赖):
测试方法:只将“问题” 输入给同一个LVLM,不给它看图片。
通过条件:模型必须回答错误。这确保了问题不能仅凭语言逻辑或常识来回答,图像信息是回答问题的必要条件。
一个问答对 (q, a) 只有同时满足以上两个条件才会被保留下来。 用论文中的公式表达就是: 
Q是最终筛选出的数据集(q, a)是一个问答对D是初始生成的总数据集Mv(q, I) = a表示模型在看到图片I和问题q时,能答对答案a(正向验证)Mv(q) ≠ a表示模型只看到问题q时,答不对答案a(反向验证)
5. 方法详解
既然CapRL的核心思想是:重新定义“好”描述的标准, 一个高质量的图像描述,应该能让一个无法看到图像的纯语言模型(vision-free LLM) 仅凭该描述就能准确回答关于这幅图像的各种问题。那么基于这个思想,我们可以设计一个解耦的两阶段流程来生成客观的奖励信号,并以此来训练图像描述模型。 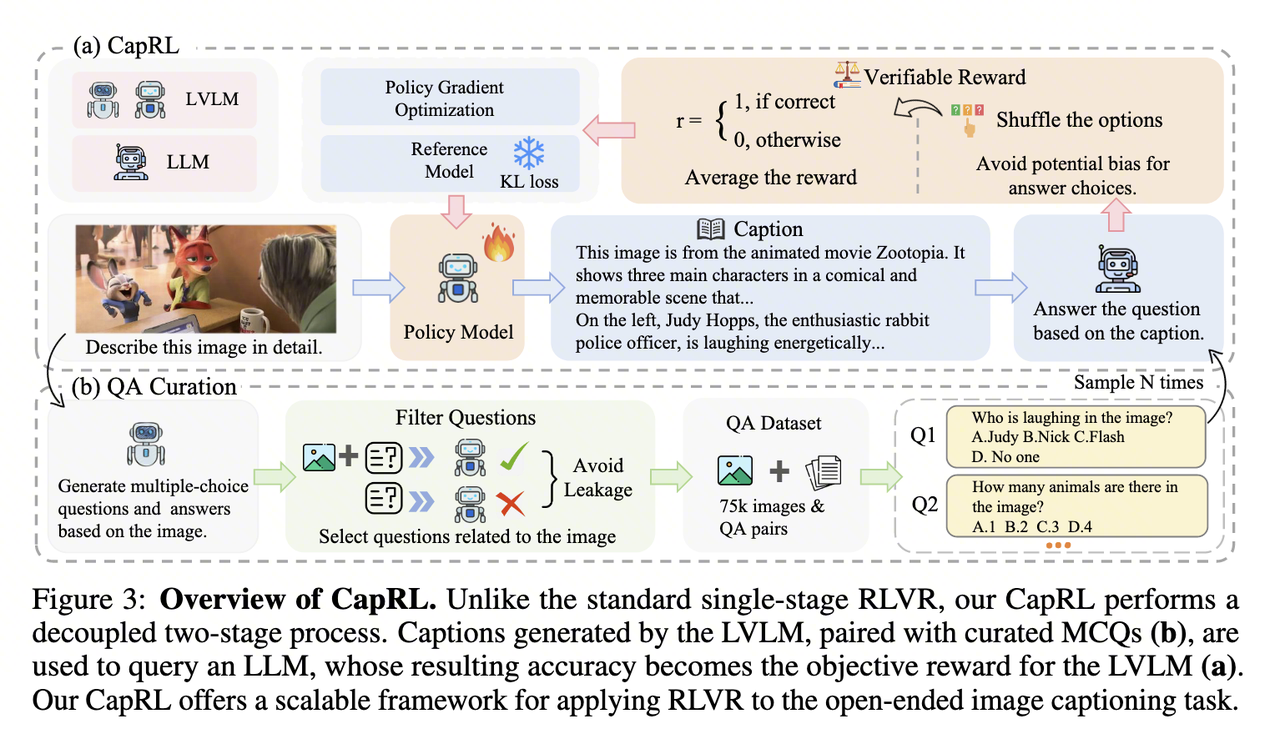
5.1 第一阶段:LVLM生成图像描述 (Caption Generation)
在这个阶段,一个大型视觉语言模型(LVLM),也就是我们需要训练策略模型(Policy Model,论文中为Qwen2.5-VL-3B),会接收一张输入的图像,并根据指令(例如“详细描述这张图片”)生成一段候选的图像描述。
5.2 第二阶段:Vision-Free LLM回答问题以评估描述质量 (Reward Calculation)
将第一阶段生成的候选描述,与该图像对应的MCQ(详见第 4 章节),一同输入到一个独立的、无法访问图像的纯文本大语言模型(LLM)Qwen2.5-3B-instruct 中,注意这里是纯文本大语言模型(LLM),它是看不到图像的,这一步完成了RL中的VQA奖励机制的解耦。 
5.3 奖励计算
这个纯文本LLM会仅根据候选描述来尝试回答问题。它的回答准确率就被直接用作奖励信号。如果LLM能够根据描述正确回答问题,就给予一个正向奖励(例如+1);反之,则为0。为了保证奖励的稳定性,模型会针对一张图片的多个问题进行回答,并计算平均准确率作为最终的奖励分数。
对于生成的描述 \(c\) 和问题集合 \(\{q_1, q_2, ..., q_n\}\):
\[R(c) = \frac{1}{n}\sum_{i=1}^{n}\mathbb{1}\left[\text{LLM}(c, q_i) = a_i\right]\]其中:
- \(c\) 是生成的图像描述
- \(q_1, q_2, ..., q_n\) 是对应的问题集合
- \(a_i\) 是第 \(i\) 个问题的正确答案
- \(\mathbb{1}[\cdot]\) 是示性函数(当条件为真时取1,否则取0)
即:纯文本LLM根据描述回答所有问题的平均准确率。 通过这种方式,CapRL成功地将一个主观的“描述好不好”的问题,转化为了一个客观的“问题能不能答对”的问题。一个描述如果包含了图像中更多的细节、更准确地刻画了物体间的关系,那么纯文本LLM依据它来回答问题的准确率自然就更高,从而获得更高的奖励。
5.4 模型优化与训练
有了客观的奖励信号后,CapRL使用GRPO算法来更新图像描述模型(即第一阶段的LVLM)。模型会不断尝试生成新的描述,并通过第二阶段的奖励机制获得反馈,从而学习如何生成能够获得更高奖励(即更高问答准确率)的描述。 整个流程形成了一个闭环:生成描述 -> 客观评估 -> 获得奖励 -> 优化模型 -> 生成更好的描述。
6. CapRL解决了什么问题?
总的来说,CapRL框架主要解决了以下几个关键问题:
克服了SFT的局限性:通过强化学习,模型不再局限于模仿固定的标注答案,而是可以在探索中学习生成更多样化、更具创造性的高质量描述,摆脱了对昂贵标注数据的依赖。
解决了主观任务的客观奖励设计难题:CapRL创新性地利用“下游任务(回答问题)”的性能来定义和量化一个开放式、主观任务(生成描述)的质量,创建了一个稳健、客观且不易被攻击的奖励机制。
提升了描述的信息密度和准确性:由于奖励直接与描述能否支持回答具体问题挂钩,该框架能有效激励模型关注并描述图像中的关键细节和复杂关系,从而生成信息更丰富、事实更准确的描述。从论文的图2可以看出,经过CapRL训练后,模型对图表和复杂场景的描述在结构、覆盖范围和准确性上都有了显著提升。
实现了可扩展的训练范式:CapRL的整个流程是自动化的,可以大规模地应用于各种图像数据,为训练更强大的视觉语言模型提供了一条高效且低成本的路径。
7. 深层思考
7.1 为什么CapRL能够奏效?
CapRL的成功并非偶然,其背后蕴含着几个值得深思的设计原则: 奖励与任务本质的对齐:图像描述的核心目标是信息传递——将视觉信息无损地转化为文字信息。传统的主观评分试图直接评价「描述写得好不好」,而CapRL则巧妙地转向评价「信息传递得完不完整」。通过问答验证,它直接度量了描述对原始视觉信息的保真程度。 将开放问题转化为封闭验证:「生成好的描述」是一个开放性任务,难以定义边界;而「回答问题是否正确」是一个封闭性验证,答案非对即错。这种转化消除了奖励信号中的主观模糊性,使得强化学习的优化目标变得清晰可追踪。 解耦设计的鲁棒性:通过将「生成」与「评估」解耦到两个独立模型,CapRL避免了单一模型自我评价时的内在偏见。纯文本LLM作为评估者,天然无法被视觉无关的「套话」所欺骗。
7.2 方法论的普适性
CapRL的核心思想——通过下游任务的表现来定义上游任务的质量——具有广泛的迁移潜力:
| 任务 | 类比应用 |
|---|---|
| 文档摘要 | 好的摘要应能支持回答关于原文的问题 |
| 知识图谱构建 | 好的KG应能支持多跳推理查询 |
| 代码文档生成 | 好的文档应能帮助开发者正确使用API |
| 数据标注 | 好的标注应能支持下游模型的准确预测 |
这种思路的本质是:当直接评价质量困难时,转而评价其功能性表现。
7.3 局限性与未来方向
尽管CapRL展现了显著的优势,仍有几点值得关注: MCQ覆盖范围的偏见:模型的「注意力分配」受限于问题集的设计。如果问题集偏重某类信息(如物体识别),模型可能忽视其他维度(如氛围、情感)。未来可探索更多样化的问题生成策略。 描述质量的多维性:问答准确率主要衡量信息完整性,但优秀的描述还应具备流畅性、可读性、逻辑组织等特质。如何在奖励函数中平衡这些维度,是一个开放问题。 评估模型的能力天花板:纯文本LLM的推理能力和指令遵循能力直接影响奖励信号的质量。随着LLM能力的提升,CapRL的效果有望进一步增强。 计算开销:两阶段的解耦设计增加了推理成本,如何在保持奖励质量的同时提升效率,值得探索。
8. 总结
CapRL为图像描述任务的强化学习训练提供了一个优雅而实用的解决方案。
8.1 核心贡献
提出了可验证奖励范式:将主观的描述质量评估转化为客观的问答验证,从根本上解决了Reward Hacking问题
设计了鲁棒的数据筛选机制:通过一正一反的双重验证,确保问题集的质量和有效性
实现了稳定可扩展的训练:无需人工标注,可大规模自动化训练
8.2 更广泛的启示
这篇工作的价值不仅在于图像描述任务本身,更在于它展示了一种务实的RL奖励设计哲学:
与其试图直接量化主观质量,不如找到一个客观可验证的代理指标,让它自然地引导模型向正确方向优化。
这一原则在当前大模型强化学习的研究浪潮中尤为重要。无论是RLHF、RLAIF还是RLVR,如何设计一个既能真实反映任务目标、又不易被模型「游戏」的奖励函数,始终是核心挑战之一。CapRL的设计思路为这一问题提供了有益的参考。
9. 延伸阅读
如果你对RLHF和奖励模型设计感兴趣,以下工作值得进一步了解:
RLAIF:Constitutional AI, Anthropic 2023 —— 使用AI反馈替代人类反馈
RLVR:DeepSeek-R1 —— 基于可验证奖励的强化学习
Self-Rewarding LM:Meta 2024 —— 让模型自我评判以实现迭代改进
Leave a Comment